At a glance
Sharon AI (NASDAQ:SHAZ), an Australian neocloud, will deploy 600PB of the VAST AI Operating System as the foundational data layer for its sovereign AI cloud, the company announced on 15 June 2026.
Using the partners’ stated benchmark of about 6PB of optimised AI storage per 1,000 GPUs, the 600PB commitment equates to a data backbone for roughly 100,000 GPUs.
That is roughly double the fleet Sharon AI has disclosed: 132MW of AI factory capacity, up to 40,000 Grace Blackwell GB300 GPUs under its NVIDIA deal, and more than 55,000 total NVIDIA GPUs expected by mid-2027.
VAST’s release highlights multi-tenant isolation and per-customer SLAs for serving multiple sovereign tenants on shared infrastructure; on our read, that separation lets Sharon AI carry government and commercial tenants on one platform without dedicating hardware to each.
The deal moves the competitive frontier for Australian neoclouds from megawatts and GPU counts toward data throughput, the constraint that determines whether expensive GPUs stay fed.
What Sharon AI committed to
Sharon AI will deploy 600PB of the VAST AI Operating System across its AI cloud, in an expanded partnership announced with VAST Data on 15 June 2026. The commitment makes VAST the foundational data layer for Sharon AI’s sovereign infrastructure, serving government, enterprise, research and AI-native customers across Australia and the Asia-Pacific.
VAST was already in Sharon AI’s stack, named in the company’s earlier deployments and in its US$950 million cloud agreement in May. This deal scales that existing relationship to standardisation at 600PB, sized against a GPU fleet that has grown quickly across 2026. The release lists the capabilities Sharon AI is buying: concurrent throughput for training and inference, native multi-tenancy with strong isolation and per-customer SLAs, built-in resilience, and integrated services such as KV cache optimisation and observability. VAST’s Disaggregated Shared Everything architecture underpins all of it, with a single global namespace so every processor can reach all data without copying petabytes between systems.
James Manning, Sharon AI’s co-founder and chief executive, framed the deal around the sovereign customer’s refusal to trade speed for control: standardising on VAST at 600PB gives the company “a rock-solid, high-performance foundation we can scale confidently.” Renen Hallak, VAST Data’s founder and chief executive, described the platform as the data foundation for “Australia’s hardest and most strategic AI ambitions.”
This is the data-layer counterpart to the compute story we have tracked all quarter, from the sovereign GPU cluster at NEXTDC M3 to that NVIDIA agreement.
A data layer sized ahead of the compute
Sharon AI and VAST anchor the deal to a benchmark of about 6PB of optimised AI storage per 1,000 GPUs for demanding large-scale workloads. Run the 600PB commitment through that ratio and the result is a data backbone for roughly 100,000 GPUs.
Set that against Sharon AI’s disclosed compute. The company’s AI factory capacity stands at 132MW, of which 102MW is contracted to end customers. Its NVIDIA collaboration scales up to 40,000 GB300 GPUs, and Sharon AI expects more than 55,000 total NVIDIA GPUs deployed by mid-2027. The data layer is therefore provisioned at close to double the GPU fleet the company expects to be running in the next 18 months.
Sharon AI’s 600PB VAST data backbone equates to roughly 100,000 GPUs, against a 55,000-plus GPU fleet expected by mid-2027
Sharon AI’s 600PB VAST data backbone equates to roughly 100,000 GPUs, against a 55,000-plus GPU fleet expected by mid-2027
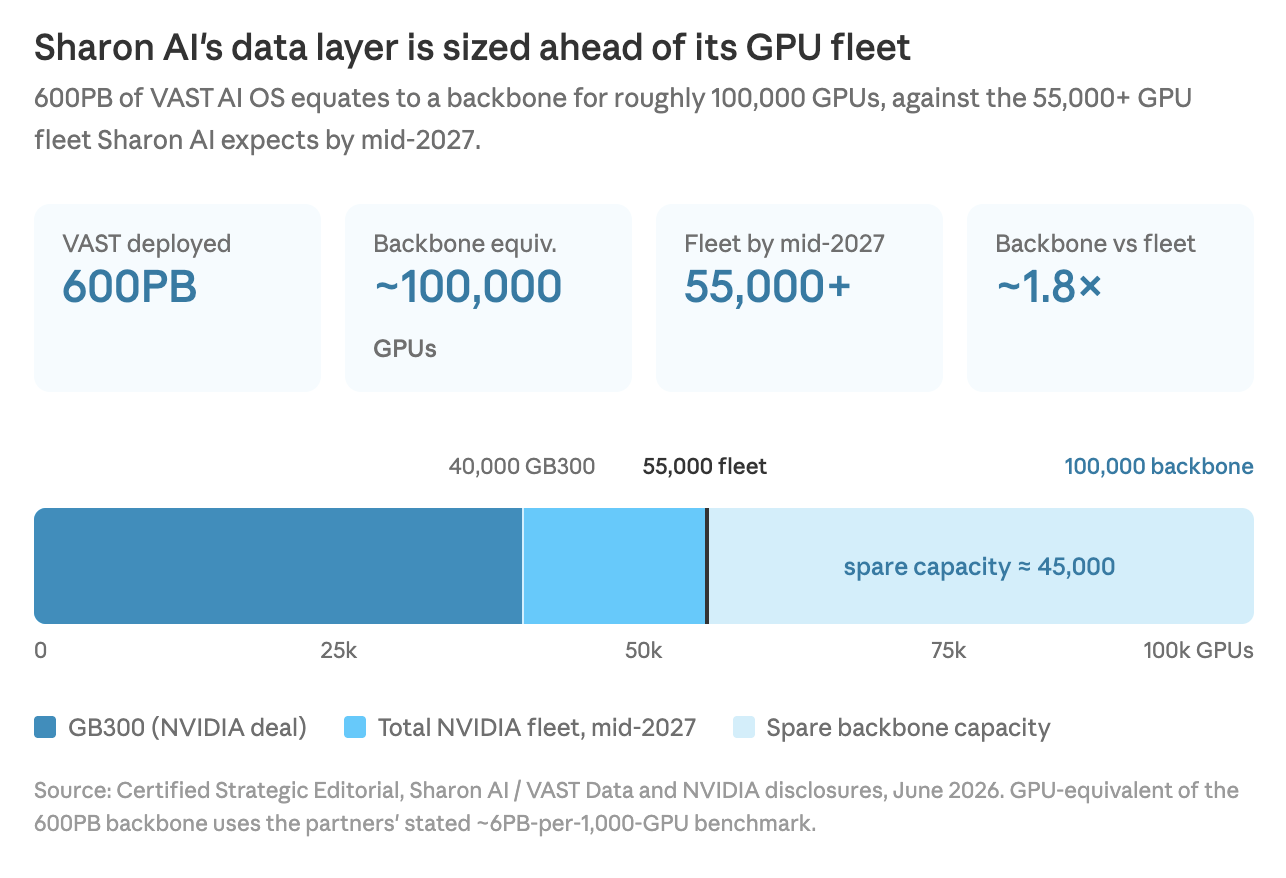
Storage provisioned ahead of compute is the reverse of the usual build order, where data infrastructure trails the GPUs it serves. Read forward, it signals where Sharon AI expects its fleet to be several procurement cycles from now, and it removes the data layer as a gating item before the GPUs that need it are installed. Sharon AI can scale GPU capacity without re-architecting storage each time, which is the practical content of the company’s claim that it can add compute “without data bottlenecks.”
Why feeding the GPUs is the constraint operators rarely name
Most coverage of Australia’s neoclouds counts two things: megawatts secured and GPUs ordered. Both matter, and we have spent the quarter on both. The VAST deal points at a third constraint that determines whether the first two pay off.
A GPU starved of data is an idle asset. At training and inference scale, the bottleneck is rarely the silicon and increasingly the rate at which storage can feed thousands of processors at once without stalling. A 40,000-GPU cluster running below its throughput ceiling because the data layer cannot keep pace is a capital-efficiency problem measured in millions of dollars of stranded compute per month. By VAST’s account, its DASE architecture and global namespace remove the copy-and-move overhead that conventional storage carries at this scale, and that is the basis on which Sharon AI is standardising on the platform.
What this means and what to watch
The VAST commitment reframes Sharon AI’s story from a compute build to an infrastructure stack, and the announcement casts that stack as sovereign infrastructure: certified at NEXTDC M3, kept onshore, and, through VAST’s per-tenant isolation, able to carry multiple customers on shared infrastructure rather than dedicating hardware to each. That framing ties to the broader onshore-capability push behind the Anthropic Australia MoU. The next disclosures worth watching are concrete. Sharon AI’s ASX secondary listing, via CHESS Depositary Interests in the June quarter, should set out how the data-layer spend sits inside the capital structure alongside the GPU commitments. The deployment schedule for the 600PB matters too, since a commitment of this size is built out in phases as customer workloads scale rather than switched on at once. And Sharon AI’s run of customer announcements, from the US$950 million five-year Asia-Pacific cloud agreement in May onward, will show whether that contracted demand is converting into recognised revenue.